Rack::Cache, tmp/cache, and running out of inodes
This is a post-mortem of how we almost let Harmony crash, hard, due to a confluence of missing knowledge and unfinished work.
Harmony is a website creation and hosting tool we run and maintain. We serve an ever increasing amount of content, from html and css to images and pdfs. As static delivery and caching is the main focus of the tool, we don’t use any Rails caching but instead manage this all our selves.
A few days ago we received a few ENOSPC errors. I had seen a number of these earlier due to our log files’ accelerated growth and had been working to get them back under control, so I figured I had missed something and another log was getting too big. So I jumped into the server, pulled up df -h and saw… free space?
| Filesystem | Size | Used | Avail | Use% | Mounted on |
| /dev/xvda1 | 7.9G | 6.4G | 1.1G | 86% | / |
| udev | 1.9G | 12K | 1.9G | 1% | /dev |
| tmpfs | 751M | 208K | 750M | 1% | /run |
| none | 5.0M | 0 | 5.0M | 0% | /run/lock |
| none | 1.9G | 0 | 1.9G | 0% | /run/shm |
So nothing was wrong? Possibly some large temp files colluded and the situation fixed itself? I decided to wait and see if this happened again. Unbeknownst to me, the server that threw the error was trying to start up Passenger and failing, taking the entire box offline. The other servers picked up the slack just fine but no-one knew this had happened.
Then the error was thrown again, and again I looked at df and saw the same thing. Growing a little concerned I pulled up our stats dashboard and saw strange Server Load entries:
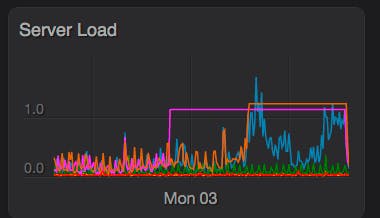
Pulling up various tools I could not tell what was causing the aberrant load values. CPU and Memory were in fine shape and the box didn’t feel at all sluggish.
Finally we got a few Pingdom alerts that parts of the site were down for very short periods of time (a minute). Doing a full sanity check of the health of the system I pulled up our load balancer status page and realized that we were now down to running on a single box!
After doing some research on what else can cause No Space errors, and noticing that passenger was indeed completely down on all the other servers because of this error, I found out about filesystem inodes and related tools, specifically df -i:
| Filesystem | Inodes | IUsed | IFree | IUse% | Mounted on |
| /dev/xvda1 | 524288 | 524288 | 0 | 100% | / |
| udev | 478049 | 388 | 477661 | 1% | /dev |
| tmpfs | 480060 | 272 | 479788 | 1% | /run |
| none | 480060 | 2 | 480058 | 1% | /run/lock |
| none | 480060 | 1 | 480059 | 1% | /run/shm |
Well crap. Every down server indeed was out of inodes, and the one remaining live server was going to run out in a matter of hours. After failing to find an obvious system-level directory with too many files or directories, I cleared out some of our older releases to get the servers live again and noticed a significant jump in now free inodes. From there I quickly tracked down the culprit:
Rails.root/tmp/cache
This directory was sitting with almost 4000 top level directories (000 - FFF, missing a few) and inside each one of those was anywhere from 2 - 10 other directories, similarly named 3 letter hash codes. Inside of these directories was a single file, a cached file from a customer’s site. Multiply these numbers again by how many previous release directories were on the system (I think 7 at the time), and it’s easy to see where all the inodes went.
So what was writing all this to tmp/cache? After a lot of digging through Rails’ ActionDispatch and Railties we came to Rack::Cache. Rack::Cache is added to the middleware if perform_caching is true. It intercepts every request, builds a SHA1 hash of the response, and stores the results in the tmp/cache hierarchy described above. We disabled Rack::Cache entirely, cleaned out the old tmp/cache directories and set up more alerting to ensure we’re notified if something similar happens again.
By the way, if you are running Rails 3.2.13 and greater, Rack::Cache is disabled by default https://github.com/rails/rails/pull/7838. We hadn’t upgraded due to the unstable nature of the release and instead just patched in the security issues this release fixed.
So to recap, a list of what happened:
- I didn’t take the “out of space” errors seriously enough
- I didn’t have a good enough understanding of the file system to track down errors
- We didn’t have alerts in place for when single servers fail
- I didn’t take oddities in our system statistics seriously enough
- We didn’t fully understand everything our Rails stack was doing
Alerts are now in place and I’ve grown a new respect for our stats gathering tools and charts, but it’s hard to really know what all a framework as big and complicated as Rails is doing under the hood. The best weapon for this is statistics and understanding the normal day-to-day functioning of the servers. When something is off, it should be investigated immediately. And do make sure that you are alerted if major pieces of infrastructure stop functioning!

Comments
Nice writeup man. I didn’t know Rack::Cache was disabled in 3.2.13+ or about “df -i”.